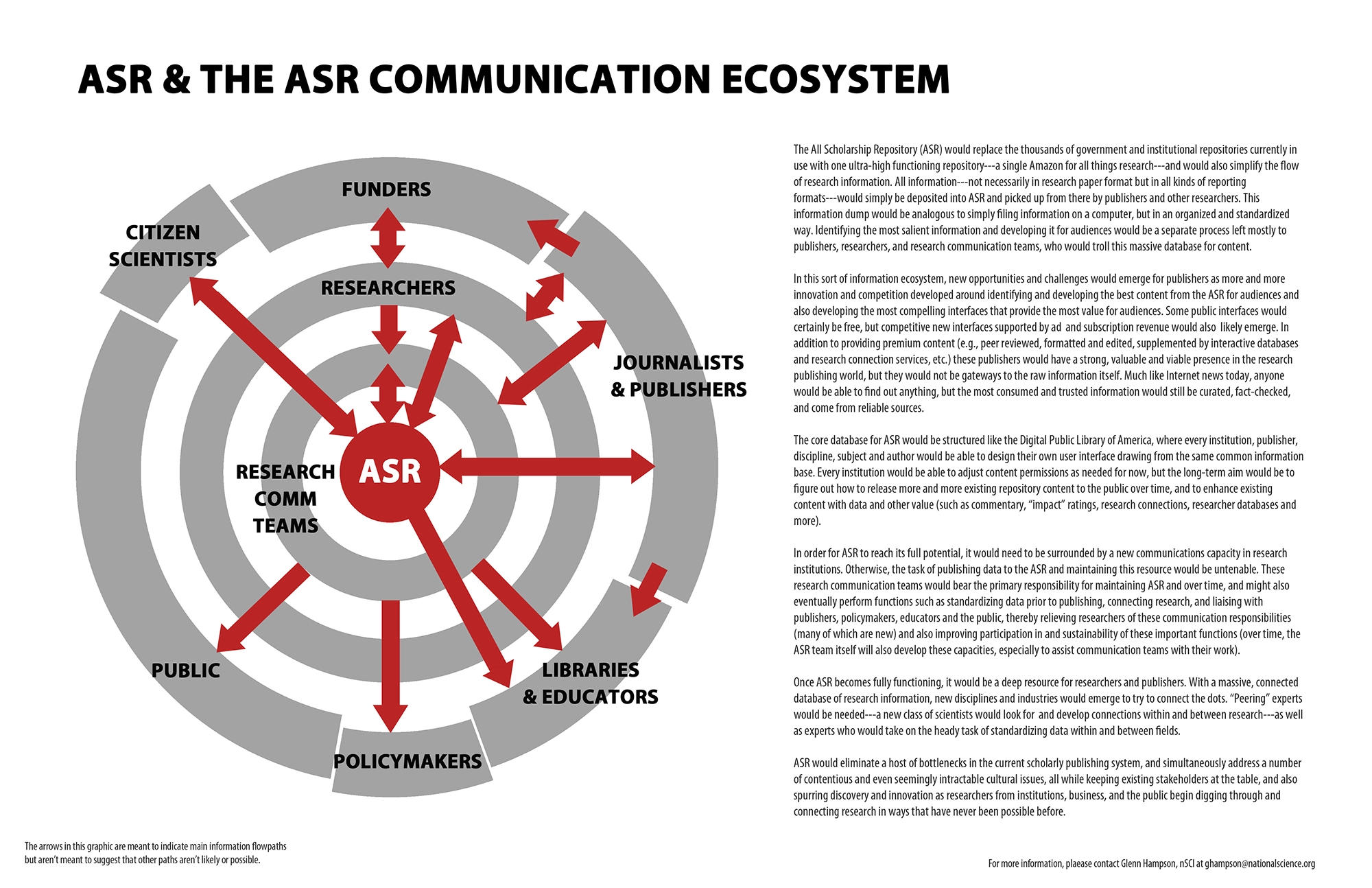
The All-Scholarship Repository (ASR) is more than just “one repository to rule all.” Rather, it represents a new way of thinking about how information is shared inside research, and how this information moves from research to the outside world. ASR is different from other repositories in three key respects: (1) ASR includes full text and data, not just metadata, (2) ASR focuses on improving usability, not just building bigger piles, and (3) ASR is community-owned and managed. A successful ASR has the potential to help us realize the full potential of open science. It will take time to build and grow—decades, in fact—but the impacts on research and society will be profound.
A variety of important initiatives are happening worldwide to integrate existing warehouses of academic knowledge (most commonly known as institutional repositories, or IRs). The main issue with integration is that research repositories are built to a wide variety of specifications, utilize a wide range of technologies, and are generally incomplete (in terms of the information they contain, the recency of their information, and the degree to which this information is accurately and completely notated). Tied to the issue of integration, the ability to “hook” into different repositories and pull out information is limited and mostly results in portals that simply provide links to articles instead of full-text resources that are truly integrated. The prospects of improving repositories are questionable: University repositories are generally not well funded and therefore may not offer a wide range of services, including metadata support or review. There also aren’t adequate incentives for depositing into repositories (and/or, there is apathy, a lack of awareness, confusion, and even disincentives in some cases). Goodwill appears to be the primary motivator at present (as the survey data bears out; see Annex 6). Therefore, the success of integrative efforts depends on the use and development of institutional efforts, as well as the ability to integrate these disparate systems into a single, usable system. It may be worth considering whether a better approach is to simply work toward building a single repository, perhaps with robust distributed capabilities to allow for continued institutional, community and discipline-level “ownership” and management of information. The current state of institutional repositories is tangled, and yet worldwide there are a number of worthy efforts trying to come to grips with the issues and solutions. Quoted here is a portion of what Richard Poynder wrote about the effort to network research repositories in May 2014 interview of Kathleen Shearer, executive director of the Confederation of Open Access Repositories (source: http://bit.ly/164kjDl):
“In October 1999 a group of people met in New Mexico to discuss ways in which the growing number of “eprint archives” could cooperate.
Dubbed the Santa Fe Convention, the meeting was a response to a new trend: researchers had begun to create subject-based electronic archives so that they could share their research papers with one another over the Internet. Early examples were arXiv, CogPrints and RePEc.
The thinking behind the meeting was that if these distributed archives were made interoperable they would not only be more useful to the communities that created them, but they could “contribute to the creation of a more effective scholarly communication mechanism.”
With this end in mind it was decided to launch the Open Archives Initiative (OAI) and to develop a new machine-based protocol for sharing metadata. This would enable third party providers to harvest the metadata in scholarly archives and build new services on top of them. Critically, by aggregating the metadata these services would be able to provide a single search interface to enable scholars interrogate the complete universe of eprint archives as if a single archive. Thus was born the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). An early example of a metadata harvester was OAIster.
Explaining the logic of what they were doing in D-Lib Magazine in 2000, Santa Fe meeting organizers Herbert Van de Sompel and Carl Lagoze wrote, “The reason for launching the Open Archives initiative is the belief that interoperability among archives is key to increasing their impact and establishing them as viable alternatives to the existing scholarly communication model.” As an example of the kind of alternative model they had in mind Van de Sompel and Lagoze cited a recent proposal that had been made by three Caltech researchers.
Today eprint archives are more commonly known as open access repositories, and while OAI-PMH remains the standard for exposing repository metadata, the nature, scope and function of scholarly archives has broadened somewhat. As well as subject repositories like arXiv and PubMed Central, for instance, there are now thousands of institutional repositories. Importantly, these repositories have become the primary mechanism for providing green open access—i.e., making publicly-funded research papers freely available on the Internet. Currently OpenDOAR lists over 3,600 OA repositories.
Work in progress
Fifteen years later, however, the task embarked upon at Santa Fe still remains a work in progress. Not only has it proved hugely difficult to persuade many researchers to make use of repositories, but the full potential of networking them has yet to be realised, not least because many repositories do not attach complete and consistent metadata to the items posted in them, or they only provide the metadata for a document, not the document itself. As a consequence, locating and accessing content in OA repositories remains a hit and miss affair, and while many researchers now turn to Google and Google Scholar when looking for research papers, Google Scholar has not been as receptive to indexing repository collections as OA advocates had hoped.”
According to Shearer, “There are numerous national and thematic repository networks around the world, which link repositories with each other. These have evolved based on unique requirements and mandates; are at different stages of development; and reflect varying levels of integration. Some national networks, such as in the UK, Portugal, Argentina, and Spain, are very cohesive and have a number of robust services supporting their repositories. Others are less developed and unified, and revolve more around a community of practice for repository managers. Broadly speaking, repository networks can be characterized as having one or more of the following aspects: community of practice, adoption of common standards for metadata and vocabularies, centralized harvester, catch-all repositories for orphan publications, and other value added services. In addition to national and thematic networks, regional repository networks are being developed to connect repositories across national boundaries.” The La Referencia repository network in nine countries at present (Argentina, Brazil, Chile, Colombia, Ecuador, and Mexico, Peru, Venezuela and El Salvador) harvests from national nodes that in turn are harvesting from institutional repositories. “The initiative,” says Shearer, “began as a project funded by the Inter-American Development Bank (IDB) and is now managed by CLARA, the organization that manages the high-speed network in Latin America.” OpenAIRE is a project funded by the EC to develop repository infrastructures in the EU. OpenAIRE aggregates the research output of EC-funded projects and makes them available through a centralized portal. Shearer notes that “OpenAIRE-compliant repositories adopt common guidelines so that content can be aggregated into the central portal. OpenAIRE, with renewed funding from the EC, will soon begin to develop other value added services such as text mining and reporting tools, which enable users to better use the content and track funded research outputs.” China is also investing in the development of institutional repositories and sees these as the main route toward open access, as opposed to gold OA.
The US is taking several different approaches to this challenge:
All of these systems—PAGES, OpenAIRE, and others— are just portals and aren’t designed to include the full text of articles (or additional research documents). And the success of all of these efforts will depend on the continued development and integration of institutional and commercial repositories. PAGES, for instance, will incorporate publisher-supplied metadata from CHORUS and link to publicly-accessible content. The reason PAGES chose this route instead of the ASR route, according to Mel DeSart, head of the engineering library at the University of Washington, dates back to the February 2013 OSTP directive encouraging the development of “a strategy for leveraging existing archives, where appropriate, and fostering public/private partnerships with scientific journals relevant to the agency’s research.” OSTP was also looking for solutions that encourage public-private collaboration to:
A single, integrated platform is, in essence, what the OSTP intended to accomplish, agrees William Gunn. “They wanted to expand PubMed Central to PubFed Central. This broke apart due to interagency politics and now each agency is to come up with their own plan. They’re overdue to submit their plans and so far only NIH and DOE are close, with DOE leaning towards CHORUS and various other agencies working on their own solutions.” What are the keys to making these systems work as hoped? According to David Wojick, “The key as far as PAGES is concerned will be providing good metadata that accurately identifies the funders of the research being reported on. This metadata is turning out to be surprisingly difficult to get from the authors, even for the publishers. PAGES also needs the publication date in order to apply the mandated embargo period. Acceptance per se is not enough. Linking to publishers and IRs on a grand scale is pretty complex.” The biggest problem with SHARE, writes Wojick, is that they are simply going to harvest whatever metadata each repository provides, “so it is not clear how much true integration we will get. They are just beginning to address that issue.”
So what might a single, connected, all-scholarship repository accomplish? One way to approach this question is to explain what the currently disconnected system cannot accomplish. Without a common platform or interoperability framework, digital fragmentation will continue to make information access worse and worse. Imagine the Internet without common standards—using computers that don’t talk to each other, don’t use a common language, and yet are supposed to work together to create a robust, dynamic, and usable pool of global knowledge. This communications dysfunction is real and immediate in science. It demands not just creating a pie-in-the-sky future, but getting a handle on the information we have right now. Take HIV/AIDS research. No single database of research exists—nothing that ties together 30 years of research studies, data, protocols, and ideas. There are silos of databases, each with their own unique data headers, but there is no standard between them (one is under development), no effort that ties all of this work together (a small trial effort is struggling for funding), and no agreement among research institutions and networks to do this on a grand scale—not even an archive of all HIV/AIDS research papers that ties everything together and helps modern researchers look back and see what’s been done already and what was learned. Even if the sole purpose of an ASR effort was to improve how we spend our increasingly scarce research dollars, we can posit that building a single, interoperable repository will save billions of dollars and vastly improve research efficiency and effectiveness. And that’s not even considering what it will do for discovery. Or considering fields outside of HIV/AIDS research. What would happen to institutional repositories and efforts like SHARE, CHORUS, PAGES, and other if a new, massive ASR was funded? Probably nothing, at least for years and years. It will take a village to pull this off, from institutions to current repository players to publishers and government agencies. This enterprise will take at least a decade to build but support will grow over time (and with it, funding and discovery). As it grows, the incentives will become the elephant in the room. For reasons of visibility, discoverability, access, sustainability, reputation, ease of use, and so on, the reasons for using this system will be obvious and the reasons for not using it will sound irresponsible. Also, a hundred new actors will enter this space—far more than there are now—and the competition this creates will drive innovation. Specifically, there doesn’t need to be just one ASR. In fact, says Glenn Hampson, the executive director of nSCI, “for reasons of sustainability, access, innovation, security, preservation, and more, there should be many, and these should be shared, linked, archived, and replicated. The first ASR should be shared with Elsevier, so Elsevier can put its own spin on the information architecture and attract users based on how well it does in this regard. The same goes for AAAS and anyone else who wants to take this data and run with it. The first ASR would be the primary, common repository, but not the sole interface. Every institution and research organization should be able to get into this system and clean up its files, add links, add profiles, add new metadata, create colloquial summaries of the research that can understood by outsiders, add databases, create connections to other research and researchers, do real-time test-comparisons of data (already being done through systems designed by LabKey in Seattle), and much more.” The right balance of carrots and sticks is needed moving forward. Writes Dee Magnoni, research library director at the Los Alamos National Laboratory, a new all-scholarship system built from the ground up can include all the incentives needed to encourage participation—“the emerging ability to feed profiles with repository content, altmetrics, ORCID and VIVO info, etc. can go a long way to building incentives.”
On the other hand, do we need to design a new system in order to have true interoperability between repositories? That’s the big question right now. Some say yes, others say no—at least not yet. It’s possible, for instance, that we can accomplish the same end-goals of an ASR by simply improving participation in existing institutional repositories (maybe through a massive sustained outreach campaign, suggests William Gunn). Or by continuing to build systems to interface with the repositories that researchers already use. “There are millions of researchers on Mendeley,” for instance, says Gunn, and “many hundreds of thousands … have up to date publication records on their profiles, suggesting one option is to leverage this work already done (and the hundreds of thousands in ORCID, for example), to fetch the publications automatically. Mendeley and ORCID have APIs & repos have deposit interfaces.” Therefore, not everyone is convinced that re-inventing the wheel (yet again) is the best way to approach this issue. Writes Richard Poynder, “While I like the idea of an ‘all-scholarship repository,’ I do wonder how practical it is. The OA movement has been promising a distributed network offering something like that for over a decade. Yet thirteen years after the OAI-PMH protocol was created to facilitate interoperability between repositories I do not believe an effective network has yet to be created, not least because repositories do not implement metadata properly. So I suspect the task is far from trivial, both in terms of the technical and metadata work needed to build the infrastructure and because of the consequent cost, both the cost of setting it up and of maintaining it. And for so long as researchers continue to go to traditional publishers to publish their work any such network is going to be in competition with those publishers, who have a number of advantages.” Indeed, Eric Van de Velde suggests that the objections to making any attempt at some version of an all-scholarship repository (either centralized or distributed) can be grouped like this:
There are many inside and outside the current OSI group who are interested in continuing this initiative to explore a single repository approach. We all recognize that institutional repositories are an important—perhaps even central—issue in the OA conversation, and therefore, are calling it out here for further investigation and effort.